Parallel Cognitive Systems Laboratory
Our key focus is on AI applications and AI hardware design.
AI Software:
Deep learning algorithm and applications (medical imaging, image understanding and enhancement, cyber security).
Parallel algorithms for cognitive agents (with AFRL).
Spiking neural network algorithms for cognitive agents (with AFRL).
Application development for spiking neural processors: Intel Loihi and IBM TrueNorth.
AI Hardware:
Deep learning hardware design.
Memristor devices, circuits, and systems.
FPGA acceleration.
We have strong collaborations with other research labs at the University of Dayton (in device fabrication, controls/robotics, and image processing), and several national labs (including AFRL, NSA, and Sandia). Additionally, we have collaborations with several other universities.
The lab consists of several researchers and graduate students.
Listing of publications from the lab.
Deep learning algorithms and applications
1. New deep learning architectures. Example: Recurrent Residual U-Net:
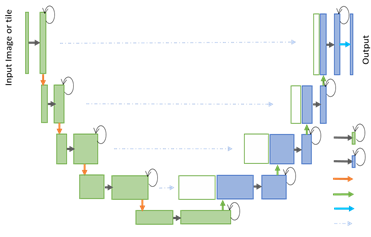 |
2. Medical imaging, and in particular, digital pathalogy.
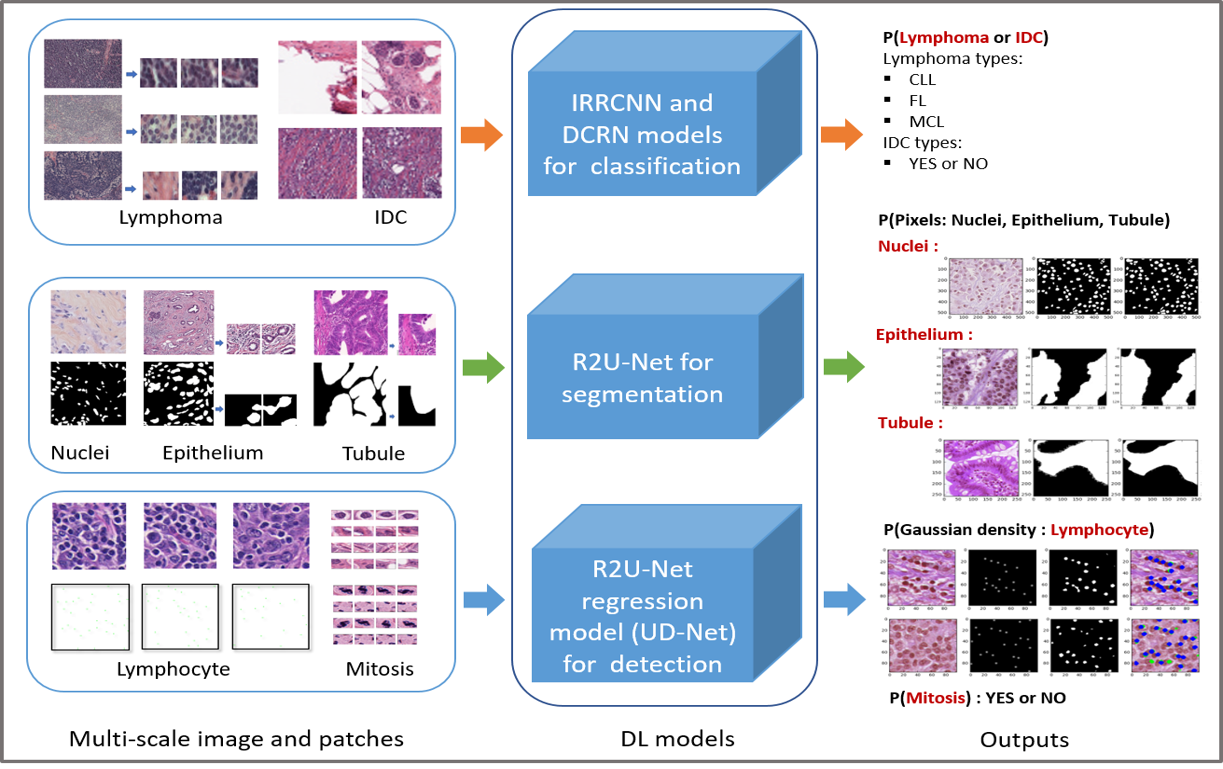 |
3. Anomaly detection and cybersecurity.
AI Hardware
We are exploring the design AI accelerator architectures: both digital and memristor based mixed signal systems.
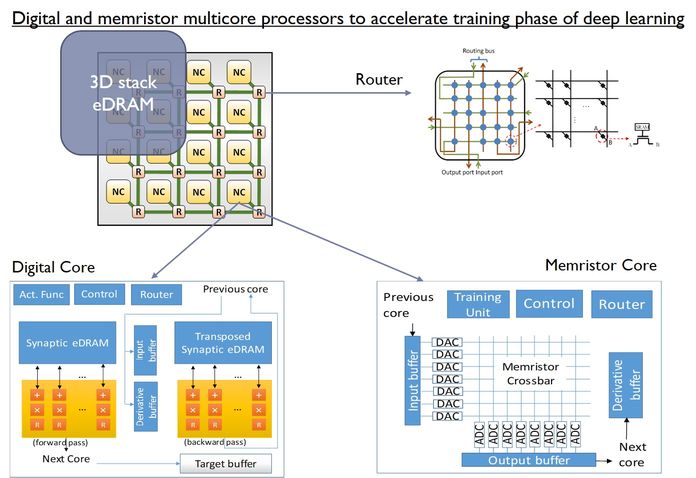 |
Multicore neuromorphic architectures: We are examining the energy, area, and throughput impact of specialized neuromorphic systems compared to traditional architectures. We have examined the following type of architectures:
Memristor based multicore recognition architectures. Our results show that these can be high energy efficient. See paper on this.
Memristor based multicore learning architectures (for deep learning). Our results show that these can be up to five orders more energy efficient than GPGPUs. See paper on this.
Digital multicore recognition architecture. We have implemented a multicore neuromorphic architecture on an FPGA and have run several applications on it.
Memristor circuits: We are carrying out detailed analysis through accurate circuit level simulations of several types of memristor crossbar based circuits. These include:
On-chip learning circuits for supervised, unsupervised, and deep learning.
Convolution network circuits.
Pattern recognition and state machine circuits (for cyber security applications).
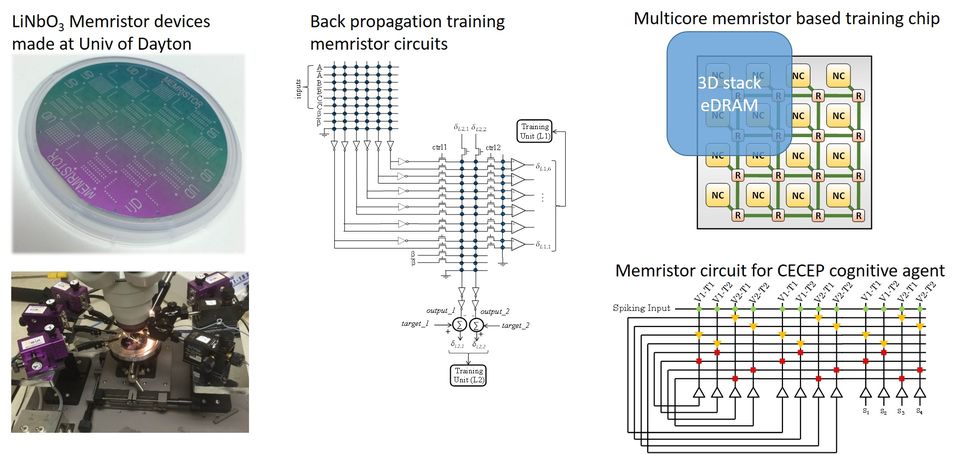 |
Memristor modeling: We have developed a flexible, yet accurate memristor device model. This model has been incorporated into the parallel SPICE simulator, XYCE, from Sandia National Labs. See XYCE Dec 2015 release notes about Yakopcic memristor model. We use this model to carry out detailed SPICE level simulations of the circuits described above.
Memristor device fabrication: Our studies show that memristors for neuromorphic systems (particularly with online learning) have different requirements than memristors for memory applications. Based on this need, we are working with other researchers at the University of Dayton and AFRL to fabricate new memristor devices.
Memristor circuits for cybersecurity applications: We have developed several circuits to carry network packet analysis for cybersecurity. These include:
Pattern recognition and state machine circuits to implement SNORT rules at very low power and area.
Unsupervised learning circuits to implement detection of anomalous network packets.
Applications of neuromorphic computing: We are porting several applications to neuromorphic computing systems, including the systems we designed, the Intel Loihi, and the IBM TrueNorth processor. Examples of these applications include:
Cognitive decision aides.
Network intrusion detection.
Target tracking.
High Performance Computing
We are exploring the parallelization and acceleration of several algorithms and applications on modern high performance computing platforms.
Acceleration of Cognitive Agents: We are accelerating autonomous agents in complex event-driven software systems (the CECEP agent from AFRL) on to high performance computers and neuromorphic architectures. This work includes:
Developing new algorithms for finite domain constraint satisfaction problems and declarative memory searching. Our new algorithms are highly parallel. We have ported them onto various parallel platforms including clusters of GPUs and Xeon Phis. Our results show up to six orders speedup compared to the conventional approaches for these algorithms.
Mapping these cognitive agents on to neuromorphic hardware: the Intel Loihi, the IBM TrueNorth processor, and memristor based systems.
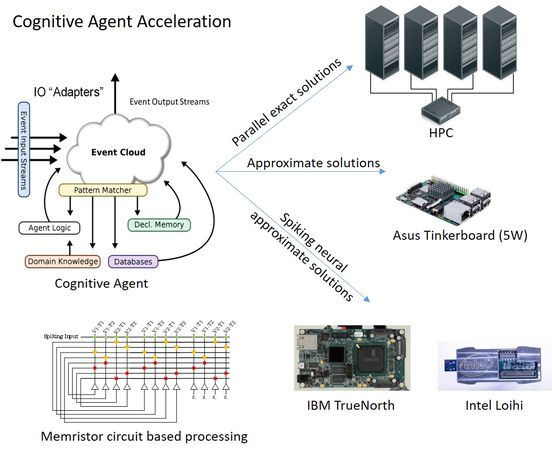 |
Acceleration of Neural algorithms: We have examined the acceleration of several neural algorithms through optimization of the algorithms and mapping onto parallel hardware. These algorithms include:
Cellular Simultaneous Recurrent Networks (CSRNs).
Spiking Networks.
Hierarchical Temporal Memories (HTM). We accelerated this by developing specialized FPGA based multi-core architectures.
Other applications parallelized and accelerated:
Finite Element Analysis
Hyperspectral Image Processing
Super-resolution algorithm